


|
|

|
|
|
||
|
|
|
This is version 2.
It is not the current version, and thus it cannot be edited. DRAFT MINUTES16 July 2003 SEEK-Taxon Teleconference, 10:00 AM US CDT Next SEEK-Taxon telecon scheduled for 30 July 2003 9/10 AM US EDT/CDT Agenda
Present: Beach, Stewart, Vieglais, Gales, Peet, Jones, Thau (invited guest) Absent: Gauch, Huddleston, Saarenmaa
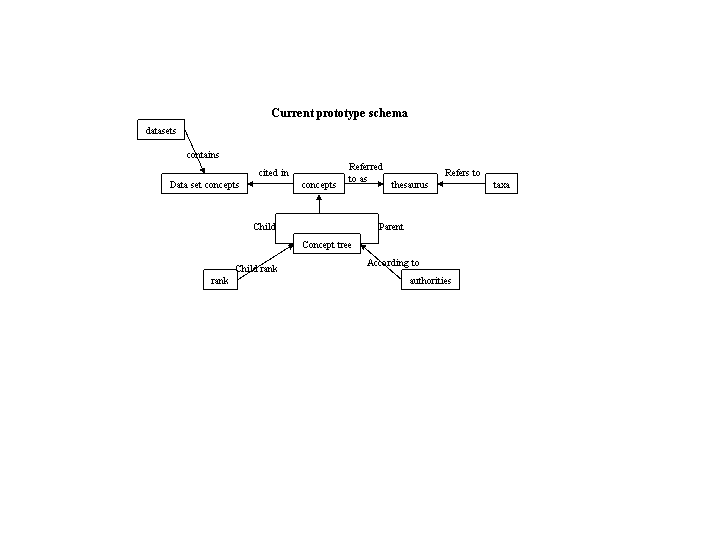
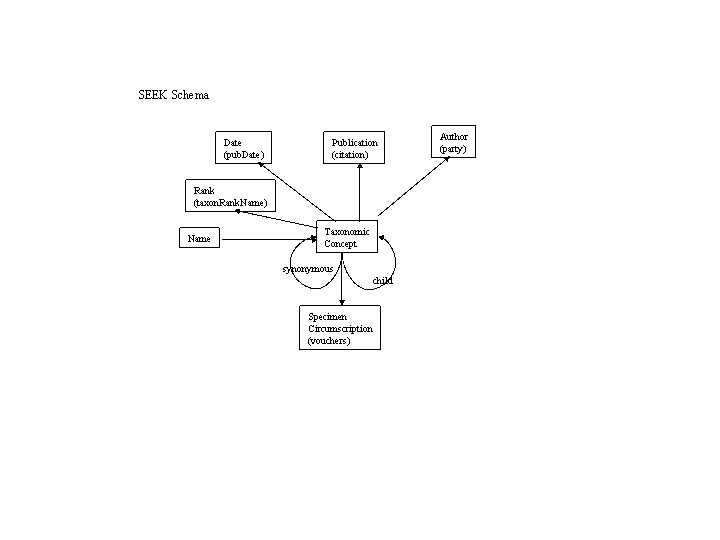
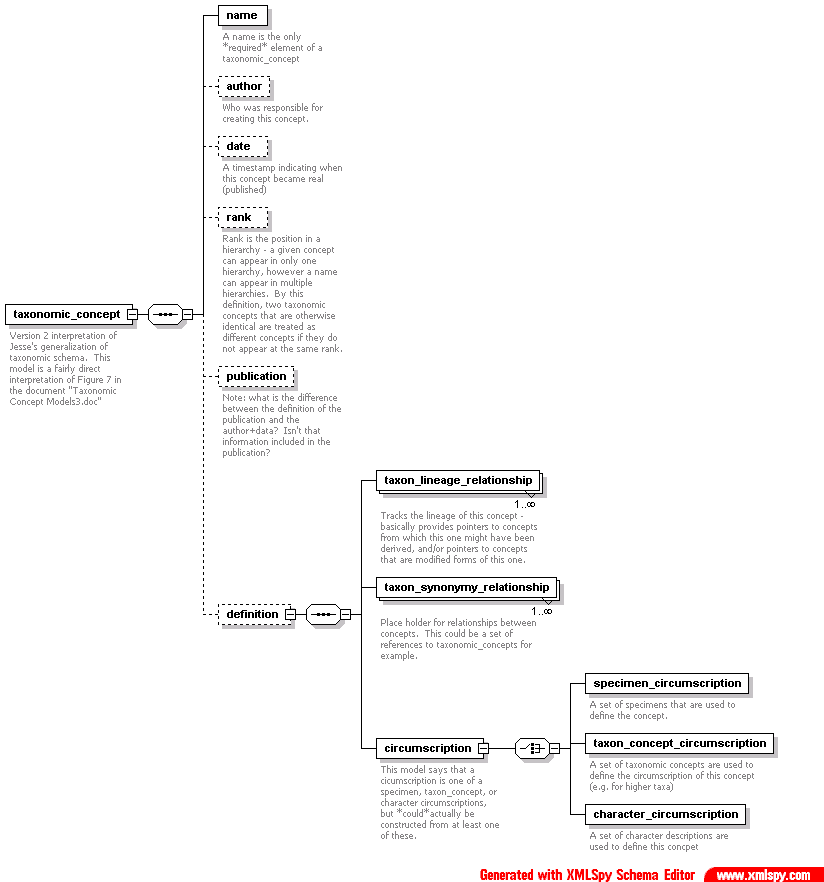
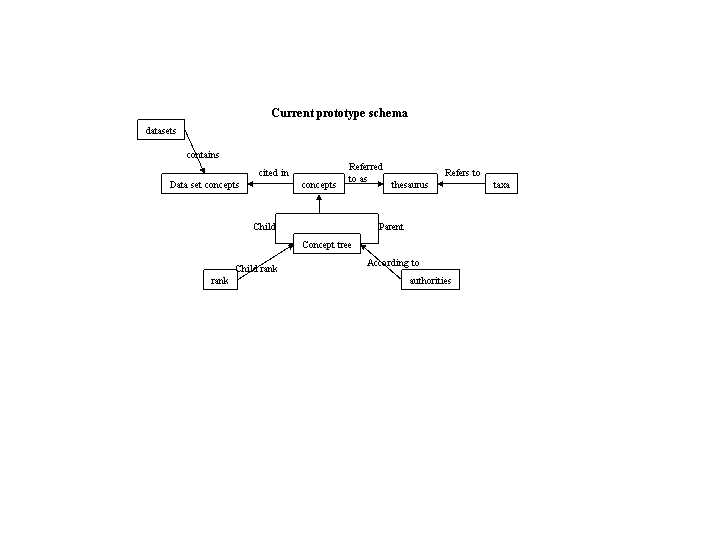
Review by Aimee Stewart of her and Rob Gales's latest demo status: http://aji.speciesanalyst.net/~astewart/ figure_7.gif Diagrams from Jesse Kennedy providing an outline of a taxonomic concept schema. An XML-Schema interpretation is below. concept_j2.png A XML-Schema representation of the above figure. The XMl-Schema document is available concept_j2.xsd.
Jessie and Dave discussed their revised schema, Aimee is ready to look at it relative to the taxon coverage in EML. Jessie thought it would be best if she and Aimee went back and forth on it. Jessie discussed the issue of whether the usage of a concept is a new concept. Jessie's thinking is that each concept has one name, and a name can apply to many concepts but that this should be modelled by defining relationships between concepts even if that concept is simply a common name. Usage by itself in our current approach does not automatically create a new concept in our model, unlike Berendsohn's model and Beach's model published several years earlier, where usage de facto creates a new concept to be mapped. Bob Peet, while accepting the proposed schema as valid and appropriate for our needs, reiterated his view that there are alternate schema possibilities. He personally prefers a version where concept is independent of the name and rank and views these as varying with party perspective. The differences are illustrated in the following 3 powerpoint slides prepared for his talk for the San Diego meeting, but which was never presented owing to a shortage of time. http://www.bio.unc.edu/faculty/peet/comparison.ppt Background discussion. For SEEK, people will use names to identify concepts, as included in data sets and for queries. We need the minimum amount needed to unambiguously identify a concept by using a name, i.e. full taxon name, author of concept, date (or publication information.) This will allow us to IDENTIFY concepts (based on names) but it will not allow us to reason about their differences. Definitions of the concepts will allow us to reason about them in various ways, depending on the kind of definition. Definitions based on synonymies, will allow some kinds of reasoning, data based on character states will allow other kinds of similarity or distance measures. Rob Gales: has put APIs on his concept database resolver demo. Matt asked for a WSDL description of those so that other groups (BEAM?) could try it out and connect with it. Discussion about the index database of names and concepts Rob and Aimee were working on. Matt points out that many queries we need to support will require data and reasoning outside of a taxon/concept index. Questioned whether to ccontinue with that for the prototype, everyone will think about it, need Susan's input on the need for this for prototyping going forward-or not. KU will hold off doing a lot more work on it now to accomodate other priorities. Discussion of the current Prototype 1 string similarity algorithm--everybody should understand that it is just a first step place holder for more sophisticated approaches later. Something had to be plugged in there for the proof-of-concept to proove the concepts. Agreement about the need to evolve this and allow user options for choosing different algorithms in the future. Discussion about how interactive the prototypes and final targets should be for end users--need to allow them to choose the algorithm they want to use and its parameters, and also to have a default matching algorithm for users that don't care or don't know which one to use. Some people want very fine concept distinctions to be used for certain groups, other want a broad brush search for concepts in large or major groups. Agreed that for the August 30th conference call we would think about development objectives for Prototype 2. Need Susan's input here. JK: would be useful to refine the matching algorithm and be able to explain the ranking for each type of algorithm. Aimee, Rob and Susan will look at additional IR methods for future prototype versions. Bob Peet will produce a sample database of taxon names for a test bed for Aimee and Rob to work with. Discussed semantic mediation briefly with Dave Thau. Matt will follow-up with Bertram and Jim, regarding our near term options and approach for beginning a semantic based approach to concepts. JK will follow-up with Bob Peet on some additional concept modelling issues.
KU Development tasksDevelopment tasks:
Attachments:
|
| This material is based upon work supported by the National Science Foundation under award 0225676. Any opinions, findings and conclusions or recomendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation (NSF). Copyright 2004 Partnership for Biodiversity Informatics, University of New Mexico, The Regents of the University of California, and University of Kansas |













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}